Jak mierzysz czy prompt działa, gdy nie ma poprawnej odpowiedzi?
Parsowanie emaili daje binarną odpowiedź - wyciągnął dane albo nie. Generowanie odpowiedzi - już nie. 'Dobry tekst' nie ma jednej poprawnej wersji. Trzy podejścia do tego problemu.
Brand Deals ma póki co dwie operacje AI:
- parsowanie przychodzących emaili od marek
- generowanie odpowiedzi negocjacyjnych
Obie korzystają z tego samego systemu promptów - modularnego pipeline’u, który składa prompt z warunkowych bloków (kontekst deala, historia korespondencji, instrukcje per akcja, schemat outputu). Obie operacje wyglądają podobnie od strony kodu.
Od strony ewaluacji to dwa różne światy.
Parsowanie ma poprawną odpowiedź
Marka pisze: “Budżet 5000 PLN, deadline 15 kwietnia, potrzebujemy 2 rolki na TikToku i 1 post na Instagramie.” Parser dostaje ten email i zwraca strukturyzowane dane - kwota, waluta, data, lista deliverables z platformami.
Testowanie jest proste. Biorę odpowiedź, parsuję na obiekt ze ścisłym schematem i sprawdzam czy wyciągnął to co powinien. Kwota 5000? Waluta PLN? Dwa deliverables TikTok, jeden Instagram? Każde pole ma binarną odpowiedź: albo trafiło, albo nie. Mogę to zautomatyzować, mogę budować zbiory testowe, mogę porównywać modele na tych samych danych.
Co więcej - do parsowania nie potrzebuję drogiego modelu. GPT-4.1 nano wystarczy. Zadanie jest ograniczone, output to JSON z typami pól, a kontekst jednoznaczny. Przy dobrze skonstruowanym prompcie tańszy model daje te same wyniki co droższy.
Generowanie nie ma poprawnej odpowiedzi
Użytkownik klika “Negocjuj warunki” - system ma wygenerować email, który odnosi się do historii korespondencji, uwzględnia aktualne warunki deala i proponuje zmiany w konkretnych polach. Prompt składa się z bloków: rola, zasady krytyczne, akcja (accept/counter/decline/ask_info), ton, długość, język, kontekst deala, wartości pól, historia korespondencji, schemat outputu.
Wynik? Email. Mogę go przeczytać i ocenić: brzmi naturalnie? Odnosi się do kontekstu? Nie halucynuje danych, których nie ma w dealu? Ale “brzmi naturalnie” to subiektywna ocena. Nie mam binarnej odpowiedzi. Nie mogę powiedzieć “ten email jest poprawny w 87%”.
I tu zaczyna się problem. Dodaję nowy blok do prompta - na przykład kontekst deliverables albo informację o niezapłaconych transzach. Generuję email. Czytam. Wygląda ok. Ale czy jest lepszy niż bez tego bloku? Nie wiem. Nie mam czym zmierzyć.
Trzy podejścia do ewaluacji generowania
A: Ręczna ocena
Czytam wygenerowany email. Oceniam. To jest moje obecne podejście i jedyne, które działa od pierwszego dnia. Problem: nie skaluje się. Przy jednej operacji AI mogę przeczytać każdy wynik. Przy pięciu - już nie. Przy produkcyjnym ruchu - fizycznie niemożliwe.
B: Proxy przez parsowanie
Pomysł: wygenerowany email przepuszczam przez ten sam parser, którego używam do emaili przychodzących. Sprawdzam czy wygenerowana odpowiedź zawiera elementy, które powinna - potwierdzenie kwoty, odniesienie do deliverables, brak danych których nie ma w dealu.
To mierzy strukturę i obecność informacji. Parsowanie wygenerowanego emaila powie mi czy model wspomniał o kwocie 5000 PLN, czy odniósł się do deadline’u, czy nie wymyślił deliverables których nie ma. To już coś - automatyczny test, który łapie halucynacje i pominięcia.
Ale nie mierzy tonu. Nie mierzy czy email brzmi jak profesjonalna korespondencja czy jak wygenerowany tekst. Nie mierzy czy “negocjuj warunki” faktycznie negocjuje, czy tylko grzecznie prosi.
To podejście właśnie zaimplementowałem.
C: LLM-as-a-judge
Pytam inny model: “Oceń ten email pod kątem naturalności, kompletności i zgodności z akcją.” Daję mu rubrykę, kryteria, skalę.
Temat jest gorący - LLM-as-a-judge ma już dedykowane badania (survey na arXiv, paper na ICLR 2025), frameworki (Langfuse, DeepEval) i ustalone praktyki. Kluczowe pytanie:
Czy niedeterministyczny system może wiarygodnie ocenić inny niedeterministyczny system?
Badania mówią: tak, ale warunkowo. Binarne oceny (“czy email wspomina o kwocie: tak/nie”) są bardziej wiarygodne niż skalowe (“oceń naturalność od 1 do 5”). Chain-of-thought prompting - wymuszenie na judge’u rozumowania krok po kroku zamiast jednej oceny - stabilizuje wyniki. A LLM-judge nie musi być idealny - wystarczy, że jest spójny. Jego rola to łapanie regresji między wersjami prompta, nie absolutna ocena jakości.
Póki co nie przetestowałem tego podejścia w praktyce. Istnieje jako opcja z dużym potencjałem, ale dopóki nie zweryfikuję jego wiarygodności ręcznie - na kilkudziesięciu przykładach, porównując oceny judge’a z moimi - to pozostaje pomysłem. Zrobiłem to później - jako kontrolowany eksperyment z trzema modelami.
Decyzja
Zaczynałem od A - ręczna ocena każdego wyniku. Szybko okazało się, że to za mało. Zaimplementowałem B (proxy przez parsowanie), które przynajmniej częściowo automatyzuje walidację promptów. Ale nadal nie odciąża mnie od czytania i oceny zwróconych tekstów - przy intensywnym testowaniu bloków prompta to wąskie gardło. C mógłby to rozwiązać.
Każdy kolejny poziom łapie inną warstwę. Parsowanie łapie halucynacje i pominięcia. LLM-judge mógłby łapać ton i naturalność. Ręczna ocena zostaje jako ostatnia instancja - ale tylko dla edge case’ów, nie dla każdego wygenerowanego emaila.
Obserwacja: model vs kontekst
Parsowanie dało mi jeszcze jedną lekcję. Instynktownie sięgnąłem po droższy model - bo wydawało się, że ekstrakcja danych z nieustrukturyzowanego emaila to złożone zadanie. Okazało się, że GPT-4.1 nano z dobrym promptem wystarczy.
Kluczowe było to, że zbudowałem PromptDebugPanel - deweloperski panel w aplikacji, który pozwala włączać i wyłączać konkretne bloki prompta, zmieniać ich kolejność i edytować cały prompt ręcznie. Widzę bezpośredni wpływ każdego bloku na wynik. Wyłączam blok z definicjami pól - parser zaczyna zgadywać typy. Włączam z powrotem - wraca do normy.
Przy generowaniu ta sama logika się rozbija. Mogę włączać i wyłączać bloki, ale nie mam czym zmierzyć “wpływ na wynik”. Widzę że email się zmienił. Nie wiem czy jest lepszy. Lepszy kontekst pomaga - mniej halucynacji, trafniejsze odniesienia do warunków deala. Ale brzmienie emaila to granica, której tani model nie przeskakuje. Negocjacyjny email wygenerowany przez GPT-4.1 nano brzmi jak wypracowanie. Ten sam prompt na mocniejszym modelu brzmi jak korespondencja.
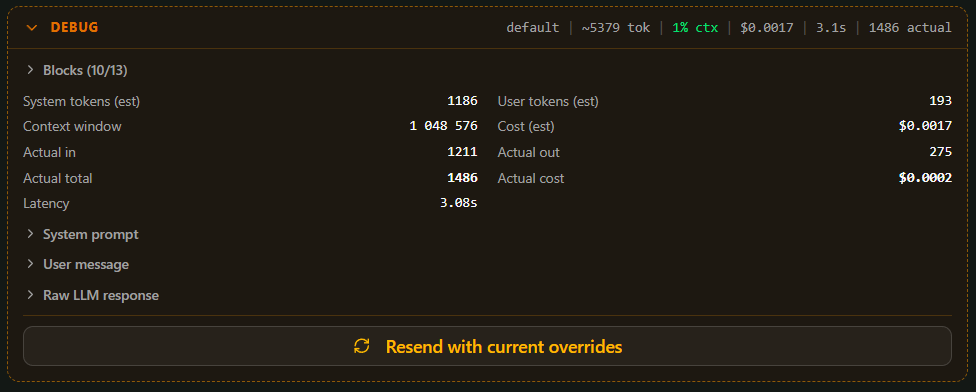 Panel do debugowania promptów w projekcie Brand Deals.
Panel do debugowania promptów w projekcie Brand Deals.
Czy to overengineering?
Pisałem o architekturze “na wyrost” w MVP - o tym, że budowałem infrastrukturę zanim miałem użytkowników. System modularnych bloków promptów z warunkami, priorytetami, sekcjami, dev overrides i panelem debugowym - to nie jest prosty prompt. To jest mały silnik.
Czy wpadłem w tę samą pułapkę? Może. Mógłbym mieć jeden string template z if-ami zamiast pipeline’u z blokami.
Ale jest różnica. Pełny CI/CD pipeline był “na wyrost” wobec produktu bez użytkowników. System promptów - chyba nie. Parsowanie i generowanie to nie feature’y dodane do aplikacji - to właśnie jest aplikacja. Jeśli nie potrafię iterować promptów szybko, nie potrafię iterować produktu.
Czy to wystarczające uzasadnienie? Zobaczę za miesiąc.
W newsletterze rozwijam tego rodzaju tematy głębiej. Zapisz się.