Okno kontekstowe LLM mierzy pojemność. Nie mierzy uwagi.
Okno kontekstowe określa ile tokenów model przyjmie, nie jak je przetworzy. Uwaga modelu ma kształt litery U - środek kontekstu dostaje jej systematycznie najmniej.
“1 milion tokenów kontekstu. AI widzi cały Twój projekt naraz. Nie musisz już nic tłumaczyć.”
Taki przekaz pojawia się w materiałach marketingowych narzędzi AI od 2024 roku - w mniej lub bardziej dosłownej formie. Brzmi jak konkretna obietnica. Technicznie prawdziwa. W praktyce myląca.
Skąd to wyobrażenie
Okno kontekstowe jest powszechnie tłumaczone jako “przestrzeń robocza modelu” albo “ilość tekstu, którą model może zapamiętać i rozważyć”. Obie metafory sugerują to samo: kontekst to pojemnik, model go “widzi”, a większy pojemnik oznacza głębsze rozumienie.
Ta intuicja jest spójna. Problem w tym, że model językowy (LLM) nie przetwarza kontekstu tak jak człowiek czyta dokument - równomiernie, od pierwszej do ostatniej linijki.
Bliższa analogia: wyobraź sobie rozmowę która trwa trzy godziny. Pytasz rozmówcę co zapamiętał. Powie Ci kontekst z początku i końca rozmowy. Fakty poruszone w środku trudno mu będzie precyzyjnie odtworzyć. Nie dlatego że zabrakło czasu żeby dokładnie omówić środkowe fragmenty - tylko dlatego że tak działa ludzka uwaga w czasie.
Jak model naprawdę przetwarza kontekst
Sercem każdego modelu LLM jest transformer - jego celem jest analiza relacji między wszystkimi fragmentami tekstu jednocześnie.
Każdy token “decyduje” ile uwagi poświęcić pozostałym tokenom w kontekście. Ta uwaga nie jest równomierna.
Rozmiar okna kontekstowego odpowiada na pytanie: ile tokenów model przyjmie. Nie odpowiada na pytanie: jak model rozłoży uwagę na to, co dostał. To dwa różne pytania z różnymi odpowiedziami.
W 2023 roku badacze ze Stanford, UC Berkeley i Samaya AI opublikowali
pracę “Lost in the Middle: How Language Models Use Long Contexts”.
Eksperyment był prosty. Model dostaje zestaw dokumentów. Tylko jeden
zawiera właściwą odpowiedź, a jego pozycja w kontekście jest
przesuwana.
Wynik: krzywa w kształcie litery U. Dokładność jest wysoka
gdy istotna informacja jest na początku kontekstu. Wysoka gdy jest na
końcu. Dramatycznie spada gdy informacja ląduje w środku. Wzorzec
powtórzył się we wszystkich badanych modelach, niezależnie od
architektury i rozmiaru okna.
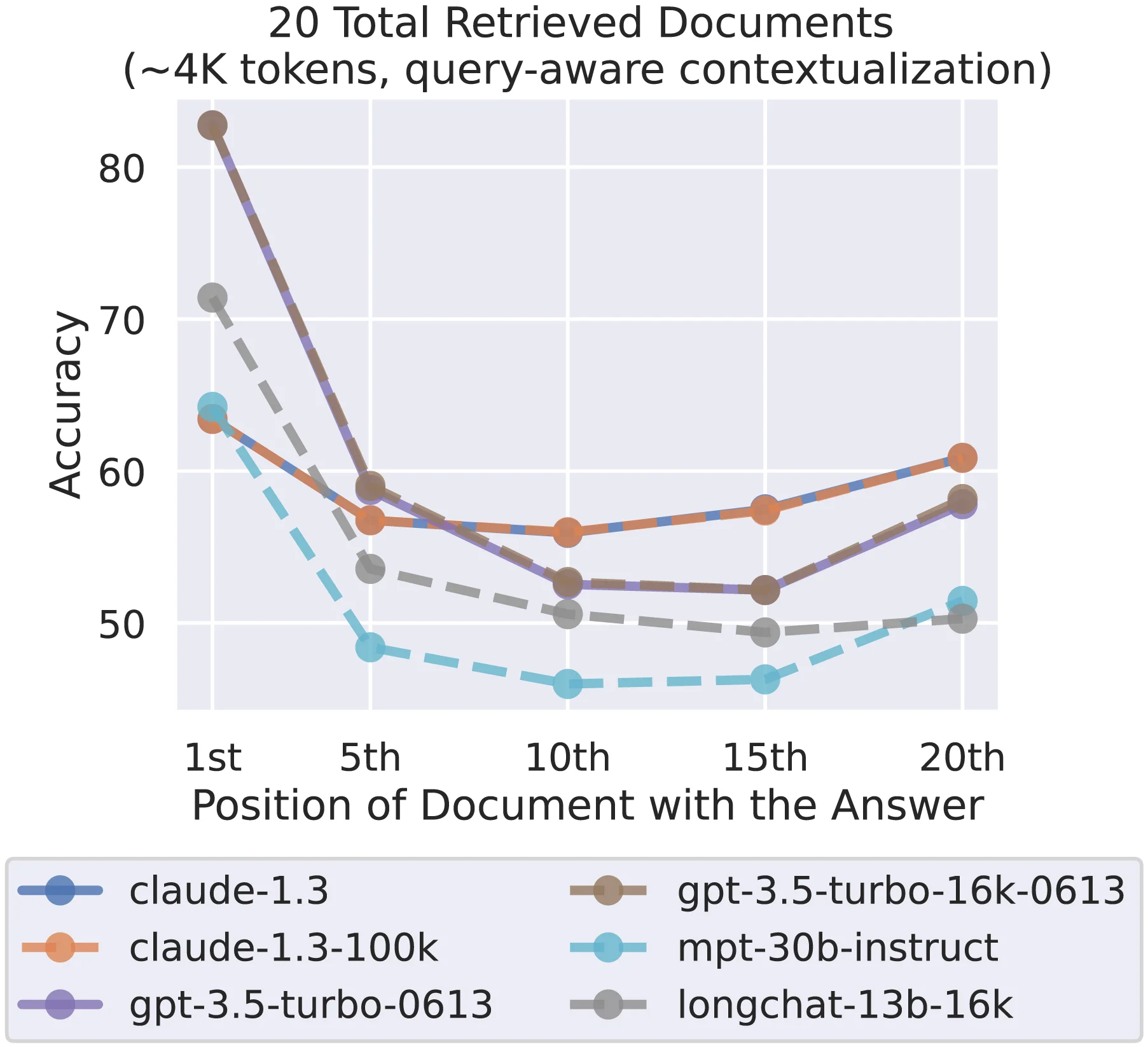
Źródło: Liu et al. (2024), “Lost in the Middle”, TACL / MIT Press. Licencja CC BY 4.0.
Dlaczego transformer gubi środek kontekstu
MIT w 2025 roku zidentyfikował dwie przyczyny architekturalne tego efektu.
Causal attention masking (maskowanie uwagi przyczynowej). Transformer - architektura leżąca u podstaw modeli LLM - generuje tekst od lewej do prawej. Token #1 jest widoczny dla każdego kolejnego tokenu w sekwencji. Token #500 - już tylko dla tokenów od #501 wzwyż. Wcześniejsze tokeny kumulują więcej uwagi nie dlatego, że model “uznaje je za ważniejsze” - ale dlatego, że architektura daje im statystycznie więcej okazji do bycia uwzględnionym przy generowaniu odpowiedzi.
Positional encoding decay (zanikanie kodowania pozycyjnego). Modele używają kodowania pozycyjnego opartego na odległości między tokenami (technika zwana RoPE). Tokeny daleko od siebie mają naturalnie zredukowaną siłę uwagi. Tokeny na końcu kontekstu są blisko miejsca generowania odpowiedzi - silne połączenie. Tokeny na początku utrzymują uwagę przez osobny mechanizm zwany “attention sinks”. Tokeny w środku: za daleko od początku, za daleko od końca. Martwa strefa.
To nie jest błąd konkretnego modelu. To właściwość architektury transformera - obecna we wszystkich aktualnych modelach produkcyjnych.
Konsekwencja jest prosta: im więcej treści wrzucasz do kontekstu, tym więcej “środka” tworzysz. Szum w kontekście nie jest neutralny - fizycznie wypycha istotne informacje w stronę strefy z najsłabszą uwagą.
Jak nie stracić informacji w środku kontekstu
Skoro uwaga modelu nie jest równomierna, z mechanizmu wynikają konkretne zasady - nie jako instrukcja obsługi narzędzia, ale jako konsekwencje architektury:
| Zasada | W praktyce |
|---|---|
| Pozycja ma znaczenie | Ważne informacje idą na początek lub koniec kontekstu, nie “gdziekolwiek pasuje” |
| Precyzja > objętość | Mniejszy, dobrze dobrany kontekst bije duży, zaszumiony - więcej środka to więcej strat |
| Struktura pomaga | Nagłówki, sekcje, tagi pomagają modelowi identyfikować co jest czym nawet przy zredukowanej uwadze |
Anthropic - producent Claude - w materiałach inżynieryjnych z 2025 roku nie skupia się na rozmiarze okna. Używa terminu “context engineering” i definiuje problem jako optymalizację użyteczności tokenów - nie ich liczby. Rozmiar okna to specyfikacja. Jakość kontekstu to osobny problem.
Granica między pojemnością a jakością
- Anthropic w ogłoszeniu 100K okna: “dropping an entire codebase into the context.”
- Google o Gemini Code Assist: “understand our entire codebase.”
- OpenAI o GPT-4.1: “1 million tokens - more than 8 copies of the entire React codebase.”
Trzej główni gracze, ta sama obietnica: wrzuć wszystko, model zrozumie.
Mechanizm mówi co innego. Więcej treści w kontekście to więcej środka. Więcej środka to więcej martwej strefy. Im więcej “wrzucasz na wszelki wypadek”, tym większa szansa że to co naprawdę ważne utonie w środku - tam, gdzie model prawie nie patrzy.
Duże okno nie gwarantuje dobrego kontekstu. Gwarantuje tylko, że więcej treści zmieści się w strefie z najsłabszą uwagą.
Więcej o tym jak zarządzać kontekstem w praktyce - w newsletterze. Zapisz się.